LUN Basics
Simply stated, a LUN is a logical entity that converts raw physical disk space into logical storage space that a host server's operating system can access and use. Any computer user recognizes the logical drive letter that has been carved out of their disk drive. For example, a computer may boot from the C: drive and access file data from a different D: drive. LUNs do the same basic job. "LUNs differentiate between different chunks of disk space. "A LUN is part of the address of the storage that you're presenting to a [host] server."
LUNs are created as a fundamental part of the storage provisioning process using software tools that typically accompany the particular storage platform. However, there is not a 1-to-1 ratio between drives and LUNs. Numerous LUNs can easily be carved out of a single disk drive. For example, a 500 GB drive can be partitioned into one 200 GB LUN and one 300 GB LUN, which would appear as two unique drives to the host server. Conversely, storage administrators can employ Logical Volume Manager software to combine multiple LUNs into a larger volume. Veritas Volume Manager from Symantec Corp. is just one example of this software. In actual practice, disks are first gathered into a RAID group for larger capacity and redundancy (e.g., RAID-50), and then LUNs are carved from that RAID group.
LUNs are often referred to as logical "volumes," reflecting the traditional use of "drive volume letters," such as volume C: or volume F: on your computer. But some experts warn against mixing the two terms, noting that the term "volume" is often used to denote the large volume created when multiple LUNs are combined with volume manager software. In this context, a volume may actually involve numerous LUNs and can potentially confuse storage allocation. "The 'volume' is a piece of a volume group, and the volume group is composed of multiple LUNs,"
Once created, LUNs can also be shared between multiple servers. For example, a LUN might be shared between an active and standby server. If the active server fails, the standby server can immediately take over. However, it can be catastrophic for multiple servers to access the same LUN simultaneously without a means of coordinating changed blocks to ensure data integrity. Clustering software, such as a clustered volume manager, a clustered file system, a clustered application or a network file system using NFS or CIFS, is needed to coordinate data changes.
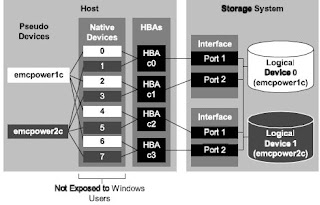
SAN zoning and masking
LUNs are the basic vehicle for delivering storage, but provisioning SAN storage isn't just a matter of creating LUNs or volumes; the SAN fabric itself must be configured so that disks and their LUNs are matched to the appropriate servers. Proper configuration helps to manage storage traffic and maintain SAN security by preventing any server from accessing any LUN.
Zoning makes it possible for devices within a Fibre Channel network to see each other. By limiting the visibility of end devices, servers (hosts) can only see and access storage devices that are placed into the same zone. In more practical terms, zoning allows certain servers to see one or more ports on a disk array. Bandwidth, and thus minimum service levels, can be reserved by dedicating certain ports to a zone or isolate incompatible ports from one another.
Consequently, zoning is an important element of SAN security and high-availability SAN design. Zoning can typically be broken down into hard and soft zoning. With hard zoning, each device is assigned to a zone, and that assignment can never change. In soft zoning, the device assignments can be changed by the network administrator.
LUN masking adds granularity to this concept. Just because you zone a server and disk together doesn't mean that the server should be able to see all of the LUNs on that disk. Once the SAN is zoned, LUNs are masked so that each host server can only see specific LUNs. For example, suppose that a disk has two LUNs, LUN_A and LUN_B. If we zoned two servers to that disk, both servers would see both LUNs. However, we can use LUN masking to allow one server to see only LUN_A and mask the other server to see only LUN_B. Port-based LUN masking is granular to the storage array port, so any disks on a given port will be accessible to any servers on that port. Server-based LUN masking is a bit more granular where a server will see only the LUNs assigned to it, regardless of the other disks or servers connected.
LUN scaling and performance
LUNs are based on disks, so LUN performance and reliability will vary for the same reasons. For example, a LUN carved from a Fibre Channel 15K rpm disk will perform far better than a LUN of the same size taken from a 7,200 rpm SATA disk. This is also true of LUNs based on RAID arrays where the mirroring of a RAID-0 group may offer significantly different performance than the parity protection of a RAID-5 or RAID-6/dual parity (DP) group. Proper RAID group configuration will have a profound impact on LUN performance.
An organization may utilize hundreds or even thousands of LUNs, so the choice of storage resources has important implications for the storage administrator. Not only is it necessary to supply an application with adequate capacity (in gigabytes), but the LUN must also be drawn from disk storage with suitable characteristics. "We go through a qualification process to understand the requirements of the application that will be using the LUNs for performance, availability and cost," For example, a LUN for a mission-critical database application might be taken from a RAID-0 group using Tier-1 storage, while a LUN slated for a virtual tape library (VTL) or archive application would probably work with a RAID-6 group using Tier-2 or Tier-3 storage.
LUN management tools
A large enterprise array may host more than 10,000 LUNs, so software tools are absolutely vital for efficient LUN creation, manipulation and reporting. Fortunately, management tools are readily available, and almost every storage vendor provides some type of management software to accompany products ranging from direct-attached storage (DAS) devices to large enterprise arrays.
Administrators can typically opt for vendor-specific or heterogeneous tools. A data center with one storage array or a single-vendor shop would probably do well with the indigenous LUN management tool that accompanied their storage system. Multivendor shops should at least consider heterogeneous tools that allow LUN management across all of the storage platforms. Mack uses EMC ControlCenter for LUN masking and mapping, which is just one of several different heterogeneous tools available in the marketplace. While good heterogeneous tools are available, he advises caution when selecting a multiplatform tool. "Sometimes, if the tool is written by a particular vendor, it will manage 'their' LUNs the best," he says. "LUNs from the other vendors can take the back seat -- the management may not be as well integrated."
In addition to vendor support, a LUN management tool should support the entire storage provisioning process. Features should include mapping to specific array ports and masking specific host bus adapters (HBA), along with comprehensive reporting. The LUN management tool should also be able to reclaim storage that is no longer needed. Although a few LUN management products support autonomous provisioning, experts see some reluctance toward automation. "It's hard to do capacity planning when you don't have any checks and balances over provisioning," Mack says, also noting that automation can circumvent strict change control processes in an IT organization.
LUNs at work
Significant storage growth means more LUNs, which must be created and managed efficiently while minimizing errors, reigning in costs and maintaining security. For Thomas Weisel Partners LLC, an investment firm based in San Francisco, storage demands have simply exploded to 80 terabytes (TB) today -- up from about 8 TB just two years ago. Storage continues to flood the organization's data center at about 2 TB to 3 TB each month depending on projects and priorities.
This aggressive growth pushed the company out of a Hitachi Data Systems (HDS) storage array and into a 3PARdata Inc. S400 system. LUN deployment starts by analyzing realistic space and performance requirements for an application. "Is it something that needs a lot of fast access, like a database or something that just needs a file share?" asks Kevin Fiore, director of engineering services at Thomas Weisel. Once requirements are evaluated, a change ticket is generated and a storage administrator provisions the resources from a RAID-5 or RAID-1 group depending on the application. Fiore emphasizes the importance of provisioning efficiency, noting that the S400's internal management tools can provision storage in just a few clicks.
Fiore also notes the importance of versatility in LUN management tools and the ability to move data. "Dynamic optimization allows me to move LUNs between disk sets," he says. Virtualization has also played an important role in LUN management. VMware has allowed Fiore to consolidate about 50 servers enterprise-wide along with the corresponding reduction in space, power and cooling. this lets the organization manage more storage with less hardware.
LUNs getting large
As organizations deal with spiraling storage volumes, experts suggest that efficiency enhancing features, such as automation, will become more important in future LUN management. Experts also note that virtualization and virtual environments will play a greater role in tomorrow's LUN management. For example, it's becoming more common to provision very large chunks of storage (500 GB to 1 TB or more) to virtual machines. "You might provision a few terabytes to a cluster of VMware servers, and then that storage will be provisioned out over time.