If you have a multihomed host and are running like :
· IBM AIX,
· HP-UX,
· Linux,
· Solaris,
· VMware ESX Server (2.5.0 or later), or
· Microsoft Windows
you must create a parameter file for Navisphere Agent, named agentID.txt
About the agentID.txt file:
This file, agentID.txt (case sensitive), ensures that the Navisphere Agent binds to the correct HBA/NIC for registration and therefore registers the host with the correct storage system. The agentID.txt file must contain the following two lines:
Line1: Fully-qualified hostname of the host
Line 2: IP address of the HBA/NIC port that you want Navisphere Agent to use
For example, if your host is named host28 on the domain mydomain.com and your host contains two HBAs/NICs, HBA/NIC1 with IP address 192.111.222.2 and HBA/NIC2 with IP address 192.111.222.3, and you want the Navisphere Agent to use NIC 2, you would configure agentID.txt as follows:
host28.mydomain.com
192.111.222.3
To create the agentID.txt file, continue with the appropriate procedure for your operating system:
For IBM AIX, HP-UX, Linux, and Solaris:
1. Using a text editor that does not add special formatting, create
or edit a file named agentID.txt in either / (root) or in a directory of your choice.
2. Add the hostname and IP address lines as described above. This file should contain only these two lines, without formatting.
3. Save the agentID.txt file.
4. If you created the agentID.txt file in a directory other than root, for Navisphere Agent to restart after a system reboot using the correct path to the agentID.txt file, set the environment variable EV_AGENTID_DIRECTORY to point to the directory where you created agentID.txt.
5. If a HostIdFile.txt file is present in the directory shown for your operating system, delete or rename it. The HostIdFile.txt file is located in the following directory for your operating system:
AIX :- /etc/log/HostIdFile.txt
HP-UX :- /etc/log/HostIdFile.txt
Linux :- /var/log/HostIdFile.txt
Solaris :- /etc/log/HostIdFile.txt
6. Stop and then restart the Navisphere Agent.
NOTE: Navisphere may take some time to update, however, it should update within 10 minutes.
7. Once the Navisphere Agent has restarted, verify that Navisphere Agent is using the IP address that is entered in the agentID.txt file. To do this, check the new HostIdFile.txt file. You should see the IP address that is entered in the agentID.txt file.The HostIdFile.txt file is in the following directory for your operating system:
AIX :/etc/log/HostIdFile.txt
HP-UX :/etc/log/HostIdFile.txt
Linux :-/var/log/HostIdFile.txt
Solaris :-/etc/log/HostIdFile.txt
For VMware ESX Server 2.5.0 and later1. Confirm that Navisphere agent is not installed.
2. Using a text editor that does not add special formatting, create or edit a file named agentID.txt in either / (root) or in a directory of your choice.
3. Add the hostname and IP address lines as described above. This file should contain only these two lines, without formatting.
4. Save the agentID.txt file.
5. If you created the agentID.txt file in a directory other than root, for subsequent Agent restarts to use the correct path to the agentID.txt file, set the environment variable EV_AGENTID_DIRECTORY to point to the directory where you created agentID.txt.
6. If a HostIdFile.txt file is present in the /var/log/ directory, delete or rename it.
7. Reboot the VMWARE ESX server.
8. Install and start Navisphere Agent and confirm that it has started.
NOTE: Before installing Navisphere Agent, refer to the EMC Support Matrix and confirm that you are installing the correct version.
NOTE: If necessary, you can restart the Navisphere Agent
NOTE: Navisphere may take some time to update, however, it should update within 10 minutes.9. Once the Navisphere Agent has restarted, verify that Navisphere Agent is using the IP address that is entered in the agentID.txt file. To do this, check the new HostIdFile.txt file which is located in the /var/log/ directory. You should see the IP address that is entered in the agentID.txt file.
For Microsoft Windows:
1. Using a text editor that does not add special formatting, create a file named agentID.txt in the directory C:/ProgramFiles/EMC/Navisphere Agent.
2. Add the hostname and IP address lines as described above. This file should contain only these two lines, without formatting.
3. Save the agentID.txt file.
4. If a HostIdFile.txt file is present in the C:/ProgramFiles/EMC/Navisphere Agent directory, delete or rename it.
5. Restart the Navisphere Agent
6. Once the Navisphere Agent has restarted, verify that Navisphere Agent is using the correct IP address that is entered in the agentID.txt file. Either:
· In Navisphere Manager, verify that the host IP address is the same as the IP address that you you entered in the agentID.txt file. If the address is the same, the agentID.txt file is configured correctly.
· Check the new HostIdFile.txt file. You should see the IP address that is entered in the agentID.txt file.


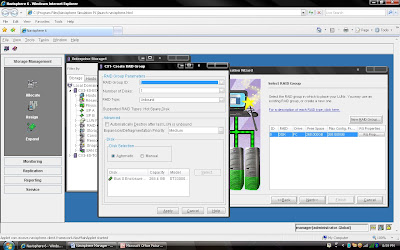
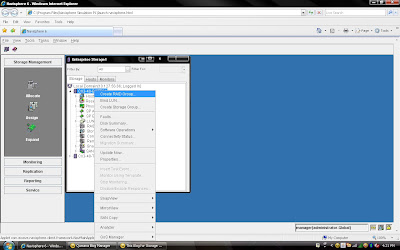 2) Once you have selected create group, it will pop up raid group creation wizard. Here you have to select so many option depending on your requirement. First select RAID Group ID. This is unique id. Then select how many disk. what it means? Let discuss for example you want to create RAID 5(3+1) then you should select 4 disk. Means there will be 4 spindle
2) Once you have selected create group, it will pop up raid group creation wizard. Here you have to select so many option depending on your requirement. First select RAID Group ID. This is unique id. Then select how many disk. what it means? Let discuss for example you want to create RAID 5(3+1) then you should select 4 disk. Means there will be 4 spindle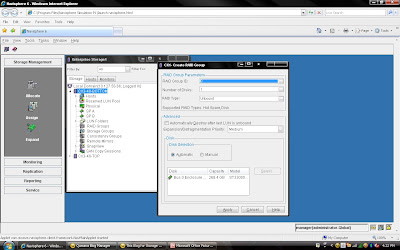 Rest, you can select default. but suppose you want to create raid group on
Rest, you can select default. but suppose you want to create raid group on 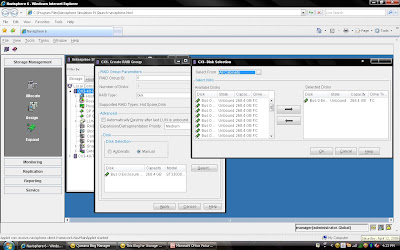 Once you have selected the all the value you can click apply. It will create RAID Group with given configuration. It will
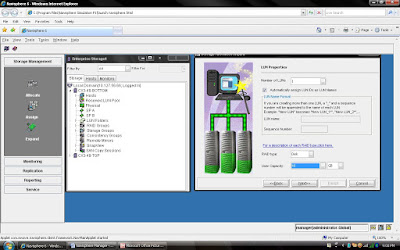
Once you have selected the all the value you can click apply. It will create RAID Group with given configuration. It will 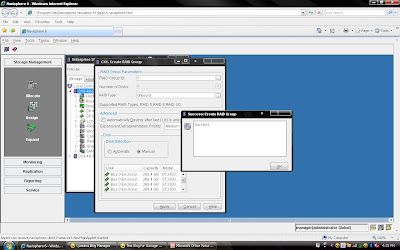 Once you have created Raid Group you can bind the
Once you have created Raid Group you can bind the 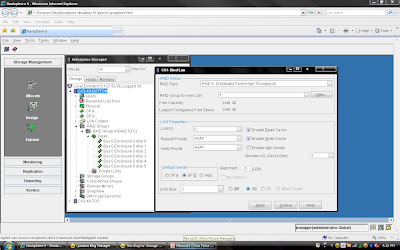
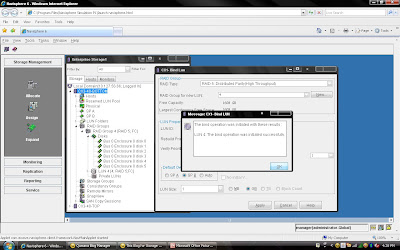 Once you have created all the
Once you have created all the